

Oracle 11g Architecture
1. What is the Oracle Architectural components ?
Oracle Architectural components segregated in two parts - Physical & Logical layer. The physical layer consists of files that reside on the disk, the components of the logical layer map the data to these physical components.
Physical layer consists of -- Datafiles, Control Files, Redolog Files
Logical layer consists of -- Tablespaces, Segment, Extents and DB Blocks
2. What are Oracle Memory Components ?
Oracles's memory structure consists of two memory areas known as -- SGA & PGA
SGA: Allocated at instance startup, and is a fundamental component of an Oracle Instance which is shared by all server and background process
Program Global Area (PGA): Allocated when the server process is started
SGA again broken into several memory components - Buffer Cache, Shared Pool, Redo log Buffer, Large Pool, Java Pool, Streams Pool, Recycle Pool etc.
3. What is the Server Parameter File ?
With Oracle 9i, Oracle came up with a small binary parameter file called SPFile, which help to start the instance (if present) and which can't be edited manually. SPFile enables DBA's to change the parameter values dynamically without bouncing the Instance.
SPFILEs provide the following advantages over PFILEs:
- An SPFILE can be backed-up with RMAN (RMAN cannot backup PFILEs)
- Reduce human errors. The SPFILE is maintained by the server. Parameters are checked before changes are accepted.
- Eliminate configuration problems (no need to have a local PFILE if you want to start Oracle from a remote machine)
- Easy to find - stored in a central location
4. What is the Parameter file ?
When an Oracle Instance is started, the characteristics of the Instance are established by parameters specified within the initialization parameter file. These initialization parameters are either stored in a PFILE or SPFILE. SPFILEs are available in Oracle 9i and above. All prior releases of Oracle are using PFILEs.
5. How do you use the INIT.ORA file ?
An INIT.ORA is a static file, client-side text file that must be updated with a standard text editor like "notepad" or "vi". This file normally reside on the server, however, you need a local copy if you want to start Oracle from a remote machine. DBA's commonly refer to this file as the INIT.ORA file.
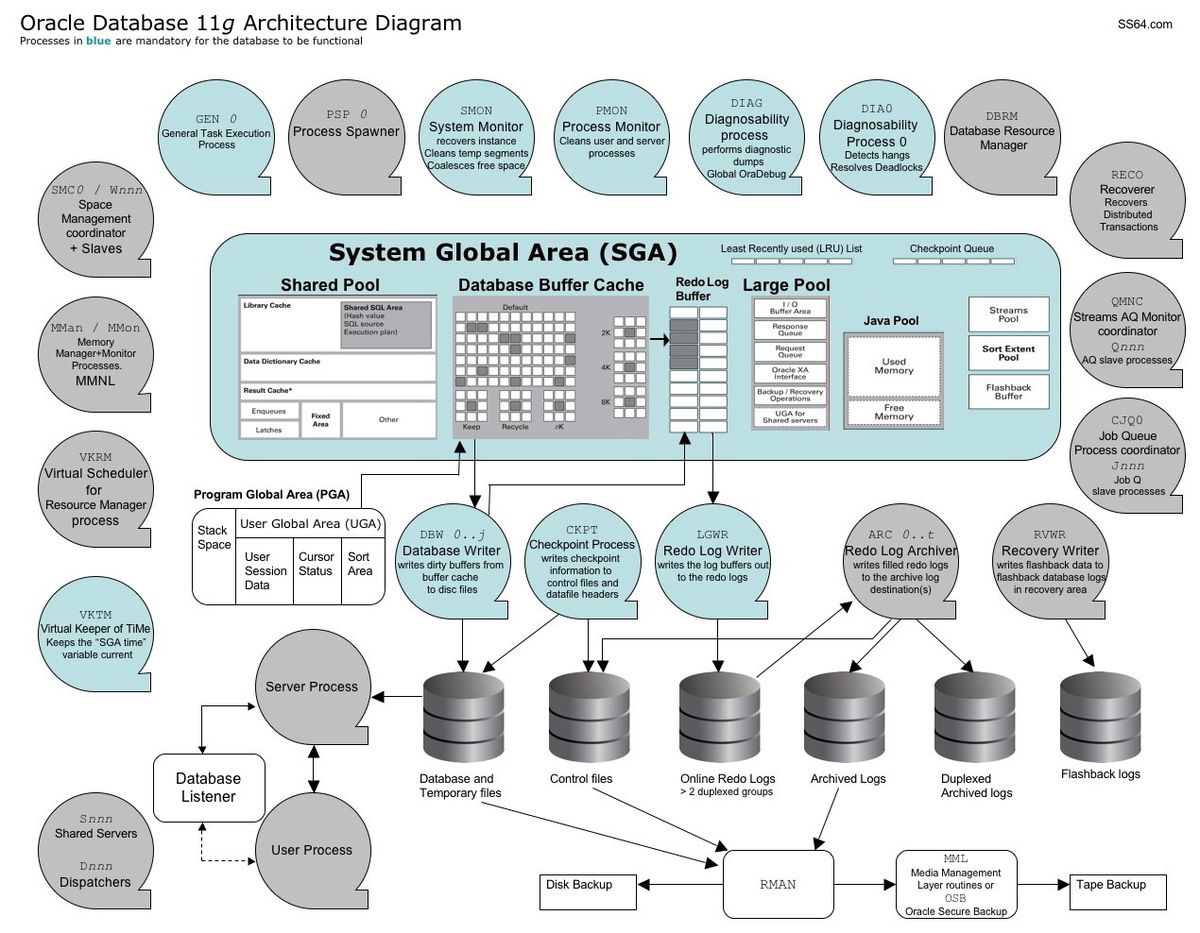
6. What is System Global Area (SGA) ?
System Global Area (SGA) is a shared memory region allocated by ORACLE that contains data and control information for one ORACLE instance and a fundamental component of Oracle Instance.
The SGA is allocated when an instance starts and de-allocated when the instance shuts down. Each instance that is started has its own SGA.
SGA again broken into several memory components - Buffer Cache, Shared Pool, Redo log Buffer, Large Pool, Java Pool, Streams Pool, Recycle Pool etc.
7. What is Shared Pool in SGA ?
Shared Pool is one of the mandatory SGA component. Shared pool is broken into two small part memories –– Library Cache and Dictionary Cache. The library cache is used to stores information about the commonly used SQL and PL/SQL statements; and is managed by a Least Recently Used (LRU) algorithm. It is also enables the sharing those statements among users. In the other hand, dictionary cache is used to stores information about object definitions in the database, such as columns, tables, indexes, users, privileges, etc.
The shared pool size can be set via SHARED_POOL_SIZE parameter in init.ora initialization parameter file.
8. What is Buffer Cache in SGA ?
Buffer cache is used to stores the copies of data block that retrieved from datafiles. That is, when user retrieves data from database, the data will be stored in buffer cache. Its size can be manipulated via DB_CACHE_SIZE parameter in init.ora initialization parameter file.
9. What does the Buffer Cache hold in SGA ?
The database buffer cache is a portion of the SGA that holds copies of the data blocks, read from datafiles.
10. What are the difference between Library Cache and Dictionary Cache ?
Library Cache and Dictionary Cache both are Shared Pool component.
The library cache is used to stores information about the commonly used SQL and PL/SQL statements; and is managed by a Least Recently Used (LRU) algorithm. It is also enables the sharing those statements among users.
In the other hand, dictionary cache is used to stores information about object definitions in the database, such as columns, tables, indexes, users, privileges, etc.
11. What is the Redo Log Buffer in SGA ?
Each DML statement (insert, update, and delete) executed by users will generates the redo entry. What is a redo entry? It is an information about all data changes made by users. That redo entry is stored in redo log buffer before it is written into the redo log files. To manipulate the size of redo log buffer, you can use the LOG_BUFFER parameter in init.ora initialization parameter file.
12. Describe the Large Pool component in SGA ?
Large pool is an optional area of memory in the SGA. It is used to relieves the burden place on the shared pool. It is also used for I/O processes. The large pool size can be set by LARGE_POOL_SIZE parameter in init.ora initialization parameter file.
13. Describe the Multi-threaded Server Process ?
Shared server / Multi-threaded Server architecture eliminates the need for a dedicated server process for each connection. A dispatcher directs multiple incoming network session requests to a pool of shared server processes. An idle shared server process from a shared pool of server processes picks up a request from a common queue, which means a small number of shared servers can perform the same amount of processing as many dedicated servers. Also, because the amount of memory required for each user is relatively small, less memory and process management are required, and more users can be supported.
A number of different processes are needed in a shared server system:
- A network listener process that connects the user processes to dispatchers or dedicated servers (the listener process is part of Oracle Net Services, not Oracle Database).
- One or more dispatcher processes
One or more shared server processes
14. What are PGA and UGA ?
The Program Global Area (PGA) is a memory region that contains data and control information for a single process (server or background). A PGA is allocated by Oracle when a user process connects to an Oracle database and a session is created. A PGA also contains a stack space to hold a session's variables, arrays, and other information. It is process specific and non-shareable.
The UGA, or "User Global Area" is another private memory structure used by a server process to maintain its state. A notable point about the UGA is that the UGA will be found within the PGA in dedicated server mode, but is moved to the SGA in shared server mode, causing the size of the SGA to grow when running in shared server mode.
15. Describe the log writer (LGWR) background process.
Log writer (LGWR) process is similar to DBWn. It writes the redo entries from redo log buffer into the redo log files.
16. How often LGWR writes user's entries to the Online Redo Log Buffer files ?
Log writer writes the redo log buffer into the redo log files when one of the following conditions met --
- At Commit
- When One-Third full
- When there is 1 MB of redo
- Every 3 seconds
- Before DBWn writes
17. Describe the Checkpoint process.
Checkpoint (CKPT) is a process to give a signal to DBWn to writes data in the buffer cache into datafiles. It will also updates datafiles and control files header when log file switch occurs.
18. How do you automatically force the Oracle to perform a checkpoint ?
We can force Oracle to perform a checkpoint using "alter system checkpoint" command at SQL prompt
19. What is the Recovery Process ?
The Recoverer process (RECO) is a process used with the distributed option.It automatically resolves failures involving distributed transactions. Periodically , it attempts to connect to the remote database and commits or rolls back.
20. What is the Lock Background Process ?
The Lock process is responsible for managing and coordinating the locks held by the individual instances. In a parallel server environment, multiple instances may attempt to mount the same database. It provides inter instance locking. Each instance in the parallel server installation has 0 - 9 lock processes assigned, corresponding to the instance number. This process has no relevance in a non - parallel server environment.
21. How does the archive process works ?
The Archiver process (ARCH) copies online redo log files to a designated storage device once they become full. Archiving will occur, only in cases when the database will be running in ARCHIVELOG mode with auto archiving enabled.
22. How do you configure your database to do an automatic archiving ?
We have to mention the destination and the naming convention of the archived logs in paramater file by defining the values of "log_archive_dest" and "log_archive_format" respectively.
We need to convert the database in archive log mode in mount phase using "alter database archivelog" command.
23. What is the System Monitor Process ?
The System Monitor process (SMON), performs instance recovery at instance start up by applying the entries in the redo log files to the datafiles. It cleans up temporary segments that are no longer needed. It also coalesces contiguous free extents (if the tablespace is locally managed) to make larger blocks of free space available.
24. Describe the Program Monitor Process Job.
The Process Monitor performs (PMON) process recovery when a user process fails. PMON is responsible for cleaning up the cache and freeing resources that the process was using. It resets the status of the active transaction table, releases locks, and removes the process ID from the list of active processes. PMON also periodically checks the status of dispatcher and server processes, and restarts any that have died. Like SMON, PMON "wakes up" regularly to check whether it is needed, and can be called if another process detects the need for it.
25. What are the differences between the SPFILE and PFILE startup ?
When an Oracle Instance is started, the characteristics of the Instance are established by parameters specified within the initialization parameter file. These initialization parameters are either stored in a PFILE or SPFILE. SPFILEs are available in Oracle 9i and above. All prior releases of Oracle are using PFILEs.
A PFILE is a static, client-side text file that must be updated with a standard text editor like "notepad" or "vi". This file normally reside on the server, however, you need a local copy if you want to start Oracle from a remote machine. DBA's commonly refer to this file as the INIT.ORA file.
An SPFILE (Server Parameter File), on the other hand, is a persistent server-side binary file that can only be modified with the "ALTER SYSTEM SET" command. This means you no longer need a local copy of the pfile to start the database from a remote machine. Editing an SPFILE will corrupt it, and you will not be able to start your database anymore.
26. What is the Control File ?
Control files are used to store information about physical structure of database, such as datafiles size and location, redo log files location, etc.
27. How do you backup your database controlfile ?
We can backup our control file in two ways --
> alter database backup controlfile to trace ;
This will generate a text backup of the control file in default location (Background Dump Destination)
or
> alter database backup controlfile to '<path>' ;
This will generate a binary backup of the control file to the user specified location.
28. What does a Control File contain ?
A control file contains the following entries:
• Database name and identifier
• Time stamp of database creation
• Tablespace names
• Names and locations of data files and redo log files
• Current redo log file sequence number
• Checkpoint information
• Begin and end of undo segments
• Redo log archive information
• Backup information
29. Describe the Password File .
The password file is an optional file in which you can specify the names of database users who have
been granted the special SYSDBA or SYSOPER administrative privileges, which enable them to perform
privileged operations, such as starting, stopping, backing up, and recovering databases.
Chapter 10 shows you how to create and maintain the password file.
If the DBA wants to start up an Oracle Instance there must be a way for Oracle to authenticate this DBA. That is if he/she allowed to do so. Obviously, his password can't be stored in the database, because Oracle can't access the database before the instance is started up. Therefore, the authentication of the DBA must happen outside of the database.There are two distinct mechanisms to authenticate the DBA: using Password file or through the operating system.
The init parameter remote_login_passwordfile specifies if a password file is used to authenticate the DBA or not. If it set either to shared or exclusive a password file will be used.
30. How do you create a password file?
If you don’t have a password file and want to create one, you need to use the orapwd utility provided
by Oracle. If you type orapwd at the operating system prompt, this is what you’ll see (on both
UNIX and Windows platforms):
$orapwd file=$ORACLE_HOME/dbs/initorclpw.ora password=oracle entries=15
31. Describe the Online Redo Log file.
The Oracle redo log files record all the changes made to the database, and they are vital during the recovery of a database. If you need to restore your database from a backup, you can recover the latest changes made to the database from the redo log files. The set of redo log files that are currently being used to record the changes to the database are called online redo log files.
Oracle writes all final changes made to data (committed data) first to the redo log files, before applying those changes to the actual data files themselves. Thus, if a system failure prevents these data changes from being written to the permanent data files, Oracle will use the redo logs to recover all transactions that committed but couldn’t be applied to the data files.